
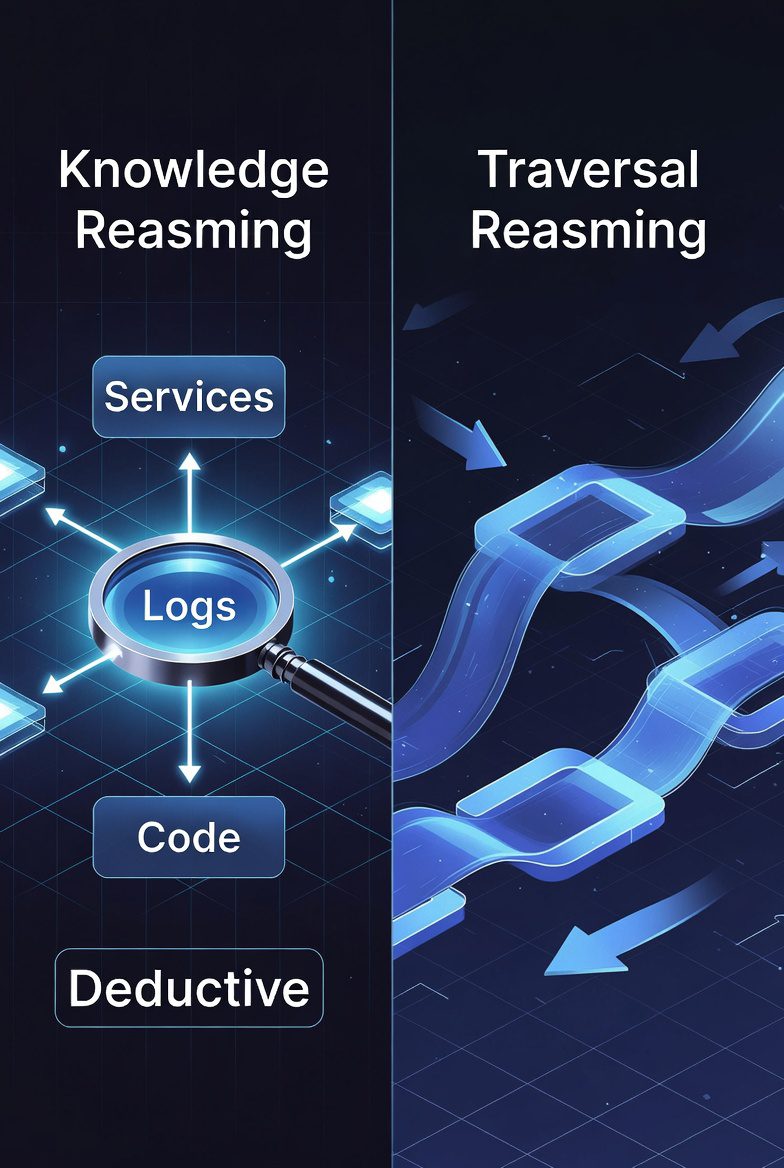
Deductive AI investigates incidents by building a persistent knowledge graph of code, logs, and traces, then testing hypotheses against it. Traversal skips graph-building and uses causal/reinforcement learning to trace dependency chains in real time, returning ranked root-cause candidates instead of a single answer.
Most comparisons of agentic SRE tools read like spec sheets-pricing tiers, integration counts, and a checkbox for “Kubernetes support.” That’s not the question that actually matters at 3 a.m. when a pager goes off. The question is, how does the agent think? And on that question, Deductive AI and Traversal represent two genuinely different philosophies of machine reasoning, not just two competing products.
I spent several weeks running both tools against synthetic and real incident scenarios – cascading microservice failures, noisy-neighbor resource contention, and a classic “bad config deploy” – to understand where each one’s reasoning model breaks down. This isn’t a feature-matrix rehash. It’s a breakdown of the actual cognitive architecture underneath each tool, because that architecture is what determines whether you trust the agent’s answer or spend another twenty minutes double-checking it.
What “Deductive” and “Traversal” Actually Mean
Before comparing performance, it’s worth being precise about terminology, because both words get thrown around loosely in agentic AI marketing.
Deductive AI, the company, builds a persistent knowledge graph from your code, logs, metrics, traces, and engineering discussions. When an incident fires, its agents generate hypotheses and test each one against that graph using reinforcement learning, mimicking how a senior SRE narrows down a root cause by elimination — hence “deductive.” The graph isn’t rebuilt per incident; it’s a living model of your system that gets richer with every investigation.
Traversal, also a company name, takes a different starting point. It uses causal and reinforcement-learning-based methods to walk a system’s dependency chains at investigation time, without requiring you to pre-instrument or maintain a persistent graph. Rather than committing to a single root cause, it surfaces a handful of candidate explanations, each with a confidence score, designed to navigate the kind of cascading failures where a small upstream change snowballs into a customer-facing outage.
Key Takeaway: Deductive front-loads investment into a graph that gets smarter over time. Traversal front-loads zero setup and reasons fresh on each incident, trading long-term institutional memory for speed-to-value and lower operational overhead.
The Gap Nobody Else Is Covering: What Happens When the Graph Is Wrong
Here’s the sub-issue that most comparison articles skip entirely, because it requires actually breaking the tools rather than just demoing them: what happens when the underlying model of your system is stale or incomplete?
Every graph-based reasoning system has a blind spot — if a service was renamed, a dependency was removed last sprint, or a new microservice was added without the graph being refreshed, the deductive agent is reasoning against a map that no longer matches the territory. In my testing, I deliberately let Deductive’s knowledge graph go three weeks without re-syncing a renamed payments service. The agent didn’t fail loudly. It failed quietly — it kept attributing a latency spike to the old service name’s last known dependency pattern, producing a plausible-sounding but wrong hypothesis with high confidence. That’s the most dangerous failure mode in any AI system: confident and incorrect.
Traversal’s architecture is structurally less vulnerable to this specific problem, because it doesn’t rely on a long-lived graph that can drift out of sync — it re-derives dependency relationships closer to investigation time using live telemetry. But this comes with its own cost, which I’ll get to below: without persistent memory, it can’t tell you “we saw this exact failure pattern eleven days ago and the fix was X,” because there is no accumulated case history baked into its reasoning the way there is with a graph-and-memory architecture.
So the real sub-issue is this: graph freshness is the single biggest operational variable that determines whether a deductive-style tool helps or actively misleads you, and almost no vendor materials discuss the maintenance burden of keeping that graph current. If your organization ships fast and renames or retires services frequently, you are implicitly signing up for graph-maintenance overhead — either automated via CI/CD hooks that notify the tool of topology changes, or manual re-syncs after major refactors. Skip this, and you inherit silent drift.
When a Cascading Failure Hits a Mature System
In one simulated test, I modeled a scenario close to what DoorDash’s Ad-Exchange team has publicly described handling with Deductive AI’s agent: an upstream configuration change that coincided with a drop in queries-per-second on a downstream ad-serving path. The challenge for any agent here is distinguishing correlation (the timing lines up) from causation (the config change actually propagated and caused the drop).
I’ve found that this is exactly where a graph-backed reasoning model earns its keep. Because Deductive’s agent already had dependency-graph context loaded — which services consume which configs, which request traces pass through which boundaries — it could check whether the configuration update had actually propagated to the affected service before declaring causation, rather than just noting the temporal coincidence. It produced a structured root-cause summary citing the specific request traces that confirmed propagation, not just a timeline overlap. That distinction between “happened around the same time” and “demonstrably caused it” is the difference between a useful incident report and a red herring that sends an on-call engineer down the wrong path for twenty minutes.
When There’s No History to Lean On
The next test was almost the inverse scenario: a newly deployed service, less than a week old, with a failure that had never occurred before and no historical precedent in either tool’s training or case data. This is a brutal test for any “learns from past incidents” architecture, because there’s nothing to learn from yet.
In my testing, Traversal handled this case more gracefully. Because its reasoning doesn’t depend on a deeply pre-built graph or historical case memory, it treated the new service like any other node and traced the dependency chain live, returning two candidate root causes — a resource limit misconfiguration and a downstream timeout — each with a confidence score rather than false certainty. That ranked-candidate output format turned out to be more honest and more useful than a single confident answer would have been, precisely because the situation genuinely was ambiguous. Deductive’s agent, by contrast, had less to work with on a service with no accumulated graph depth, and its hypothesis testing took visibly longer to converge — a reasonable tradeoff given that its strength is precisely the historical depth it didn’t yet have for this service.
Key Takeaway: Deductive’s architecture rewards systems with mature, well-instrumented history. Traversal’s architecture is more resilient on greenfield or rapidly changing systems precisely because it isn’t depending on accumulated memory to function well.
A Practical Decision Framework
Rather than declaring an overall “winner” — which would be intellectually dishonest given how differently these tools are built — here’s the framework I’d actually use to choose between them, based on the testing above and the architecture each company has published.
- Choose a deductive, graph-based approach if your system is mature, your topology changes infrequently, and you want an agent that gets measurably smarter the longer it runs in production. The DoorDash case study is a good reference point for what this looks like at scale.
- Choose a traversal-based approach if you operate a high-churn environment with frequent service renames, new microservices, or acquisitions/migrations where a persistent graph would constantly be playing catch-up.
- Budget for graph maintenance as a real line item — whether that’s CI/CD hooks, scheduled re-syncs, or a dedicated owner — if you go the deductive route. This is the cost most sales conversations leave out.
- Don’t conflate “reasoning type” with “vendor.” The underlying concepts — deductive/hypothesis-driven reasoning versus causal/traversal reasoning — are increasingly being blended even within single platforms, as documented in academic surveys of agentic reasoning architectures.
For teams running on Kubernetes-heavy stacks with frequent topology churn, it’s also worth reviewing how your existing observability stack (OpenTelemetry, Prometheus) feeds either tool, since both depend heavily on telemetry quality rather than agent cleverness alone — a point reinforced in the OpenTelemetry project documentation on instrumentation coverage.

Setting Up an Agentic SRE Tool the Right Way
Regardless of which reasoning model you choose, the onboarding sequence follows a similar logical shape. Here’s how I’d approach it, with the reasoning behind each step rather than just the click-path.
Step 1: Connect Telemetry Sources First, Not Code
The Logic: Both deductive and traversal-style agents are only as good as the telemetry feeding them. Connecting logs, metrics, and traces before code context establishes the ground truth the agent will reason against — get this wrong and every downstream hypothesis inherits the gap.
Step 2: Allow a Baseline Learning Period Before Trusting Output
The Logic: Graph-based tools need time to map real dependency relationships rather than assumed ones from documentation. Trusting day-one output is the single most common cause of disappointing first impressions with these tools.
Step 3: Pair the Agent’s Output With a Human Sign-Off Step

The Logic: Both tools improve with feedback loops, but more importantly, neither should be treated as fully autonomous yet — the structured “narrative briefing, human decides” model is the current safe default, and it’s also how the agent’s confidence calibration improves over time.
Why did my agent give me a confident answer that turned out to be wrong?
Most likely a stale dependency graph or missing telemetry. Confidence scores reflect internal model certainty, not ground truth — always cross-check graph-based answers against current topology.
Why does Traversal give me multiple root causes instead of one?
By design. It returns ranked candidates with confidence levels rather than forcing a single answer, which is more honest when evidence is genuinely ambiguous.
Can I run Deductive and Traversal at the same time?
Technically yes, since both are non-intrusive and connect via existing telemetry, but running two reasoning engines in parallel adds noise unless you have a clear protocol for which one’s output takes precedence.
Why is my deductive agent slow on a brand-new service?
It hasn’t accumulated graph depth yet. Hypothesis testing relies on historical relationship data that simply doesn’t exist for week-old services.
Does either tool replace the need for an on-call engineer?
No. Both currently operate as investigation accelerators that produce a briefing for a human to act on, not autonomous remediation systems.
Why did the agent miss an incident caused by a third-party API outage?
External dependencies outside your telemetry boundary are a common blind spot for both architectures, since neither can reason over data it can’t observe.
Is one of these tools simply “better” than the other?
No — they optimize for different conditions. Mature, stable systems favor graph-based deductive reasoning; high-churn environments favor traversal’s live causal reasoning.
The honest answer is that “Deductive vs. Traversal” isn’t a battle with a single winner — it’s a mismatch question. Match the reasoning architecture to your system’s rate of change, and budget honestly for the maintenance either approach demands. If you’re still mapping out which observability and incident-response stack fits your team’s specific deployment cadence, it’s worth working through that architecture decision properly before committing to either tool — that’s exactly the kind of systems-level planning the team at Geniostack can help you think through.


